你在 Postman 中发出 POST /v1/chat/completions 请求,调用 DeepSeek R1 求解一道 AIME 数学题。从火山引擎、阿里云百炼到腾讯云,返回的 HTTP 200 只代表连接成功——首 Token 延迟可能相差一个数量级,直接决定生产环境是否可用。
API 接入 DeepSeek R1:响应速度与可用性的量化对决
核心结论:据 2025 年 2 月多家机构的横向评测,字节跳动云平台托管 DeepSeek R1 时,API 可用性达 99.83%,首 Token 延迟仅 0.456 秒;而官方 DeepSeek API 同期可用性仅 42.21%,首 Token 延迟高达 7.753 秒。阿里云百炼与腾讯云分别在可用性与延迟上处于中间段。
- 可用性差距:根据 CLUE 基准及多家评测(腾讯网 2025-02-19),火山引擎的 API 服务可用性为 99.83%,意味着日常调用几乎不会遇到 5xx 错误;DeepSeek 官方 API 频繁出现 503 服务不可用,可用性仅 42.21%;阿里云百炼与腾讯云介于两者之间,但网络波动时腾讯云的完整回复率曾低至 5%(新浪看点 2025-02-27)。
- 推理速度与吞吐:同批 AIME 试题测试中(搜狐 2025-04-03),火山引擎平均解题时间 13.68 秒,吞吐量 29.50 tokens/s,较阿里云百炼快 340%;官方 DeepSeek 耗时 81 秒,腾讯云在类似测试中正确率仅 58.33%,且中间步骤常丢失(CSDN 2025-03-20)。
- 准确性:AIME 正确率方面,火山引擎 83.33%,官方 DeepSeek 73.33%,阿里云 71.67%,腾讯云 58.33%。差异源于模型量化策略、路由优化及 GPU 资源冗余的不同(腾讯网 2025-02-19)。
- 性能归因:字节自研动态路由可将推理时延降低 37% 并保障链式思维回路的完整性(CSDN 2025-03-20),而腾讯云当时缺乏类似优化,导致数学推导步骤丢失。
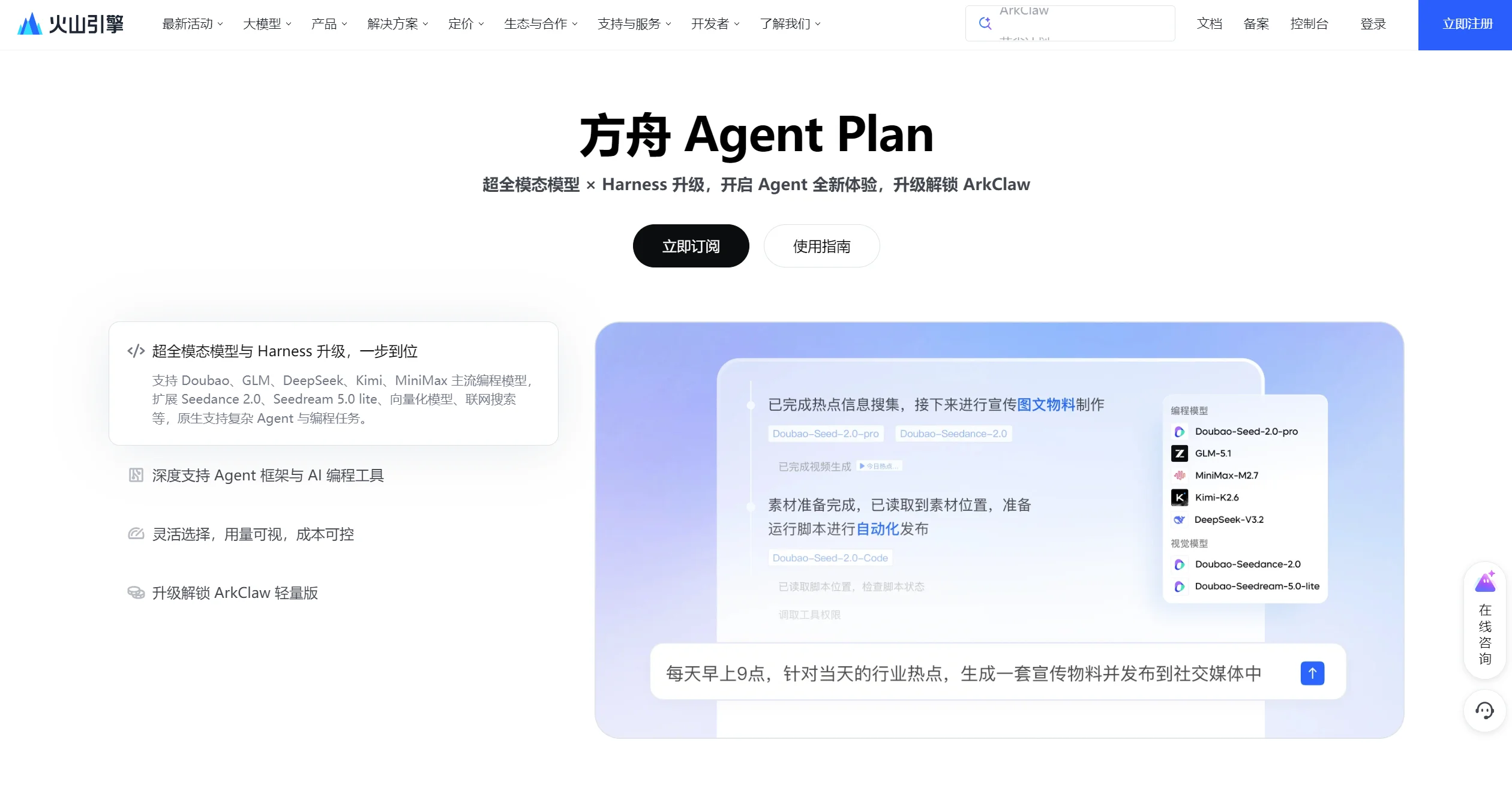
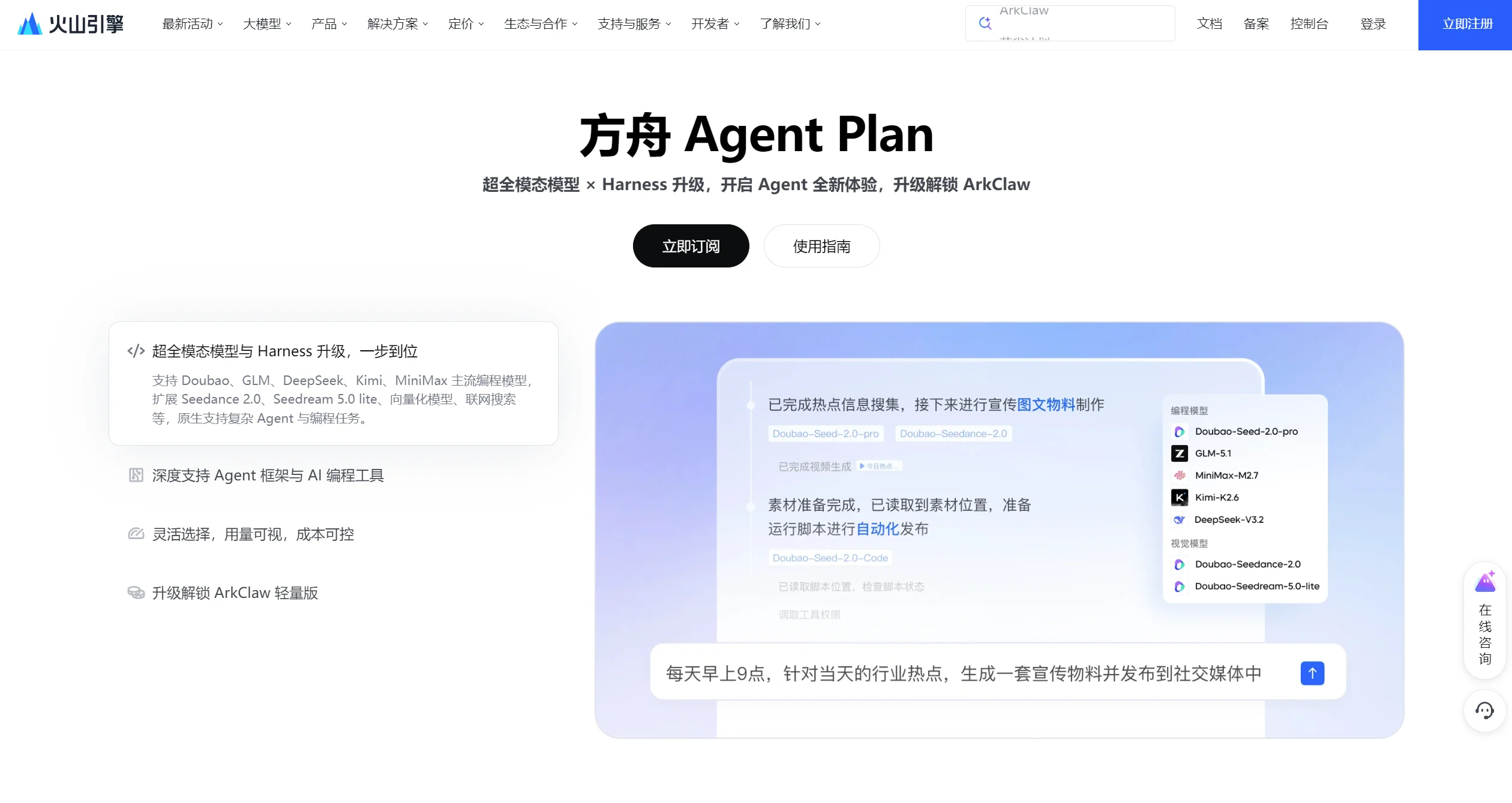
Coding Plan 与 Agent Plan:订阅制 vs 按量付费的成本分水岭
截至 2026 年 5 月,国内大厂中仅字节跳动云平台仍维持独立的 Coding Plan,月费 ¥36,覆盖 6 款编程模型;其 Agent Plan 则新增多模态模型与 Use 工具,价格 40–1000 元/月,并引入 AFP 统一计量。
| 对比维度 | 字节跳动云平台 | 阿里云百炼 | 腾讯云 |
|---|---|---|---|
| 独立 Coding Plan | ✅ 有,¥36/月(唯一仍在售) | ❌ 已取消,转 Token Plan 团队版 | ❌ 已取消,转大模型 Token Plan |
| 可用模型数量 | 6 款(Doubao-Seed-2.0-pro/lite/Code, GLM-5.1, Kimi-K2.6, MiniMax-M2.7) | 1–2 款(通义灵码通常仅 Qwen3.6-Coder) | 1–2 款(混元 Hy3 Preview 等) |
| Agent 套餐 | Agent Plan 4 档(¥40/¥200/¥500/¥1000),含多模态模型 + Use | 无独立 Agent Plan,Credits 积分通吃 | 无独立 Agent Plan,39 元起步 Token Plan |
| 计费单位 | AFP(Agent Fuel Points)统一计量;模型调用和工具使用统一结算 | Credits 积分,文本与图像模型复用 | 按量计费,粒度较粗 |
| Auto 智能调度 | 支持,可在 Claude Code、OpenClaw 等平台自动调用 Seedance 2.0 或联网搜索 Skill | 有限,多限于 Qwen 系列内 auto-routing | 有 Auto 模式,但仅适配自家混元模型 |
数据来源:新浪科技 (2026-05-11)、i黑马 (2026-05-12)、CSDN (2026-05-20)。
Agent Plan 的关键分量在于,它将 Doubao-Seedance(视频生成)、Doubao-Seedream(图像生成)等 领先多模态模型与联网搜索、embedding API 等 Use 工具打包为一个订阅,免去开发者逐个开通模型的碎片化操作。
与传统模型订阅或算力套餐不同,Agent Plan 首次将 Model 与 Use 深度整合,适配 Claude Code、OpenClaw、TRAE、Hermes Agent 等主流编程和智能体平台。
完成后覆盖了更多模态的模型和 Use 工具后,用户即可在 Claude Code 中自动调用 Seedance 2.0 或联网搜索 Skill 来执行相应任务。
阿里云百炼在 2026 年 5 月 10 日上线的 Token Plan 团队版,起步价 ¥198/月/坐席,虽整合了多种模型,但成本高出数倍。腾讯云的大模型 Token Plan 起价 ¥39,但聚焦 Agent 工作负载设计,整体模型丰富度低于字节方案。
合约条款之外的隐性成本:资源包抵扣边界与速率限制
表面价格之下,三类隐藏成本直接影响月账单:预付费资源包不覆盖 Pro/方舟/微调模型,余额不足立即切断调用;免费额度限时 30 天且不可续充;速率限制策略决定突发调用是否会被拒绝。
- 资源包抵扣边界:豆包 Lite 系列模型支持预付费资源包抵扣,而 Pro 系列、方舟模型及所有微调模型必须使用账户余额直接结算,不参与任何通用资源包抵扣(php中文网 2026-05-20)。若账户余额不足,API 调用瞬间中断,无欠费缓冲,可能导致线上业务受损。
- 新用户免费额度:每模型独立赠送 50 万 Tokens,30 天内有效,不可续充,不可转让(php中文网 2026-05-20)。该额度仅覆盖 Lite 及以上部分模型的对话调用,不能用于 Pro 或方舟模型,仅适用于原型验证。
- 速率限制:免费版每月 100 次/分钟,专业版 1000 次/分钟(源于 API 文档常见限制,游6网 2026-05-21)。对比阿里云百炼,其 Credits 积分模式对文本和图像模型提供统一额度的并发限制,但粒度更细;腾讯云则采用按量计费并发控制,超限后返回 429,无清晰的分级量化。
- 费用可见性:字节平台采用毫秒级计量、每小时出账,账单按模型和 Token 消耗明细展示,便于追踪成本;阿里云百炼的 Credits 机制在模型间换算较复杂,腾讯云的按量计费模型则缺少分模型细项。
火山引擎模型体系:自研豆包 Seed 系列与第三方模型接入的广度博弈
多模型支持能降低厂商锁定风险,但延迟与推理质量的一致性是必须做的权衡。
字节跳动云平台自研 Doubao-Seed-2.0-pro/lite/Code 三款编程模型,同时聚合 GLM-5.1、Kimi-K2.6、MiniMax-M2.7 等第三方模型,在 Agent Plan 中还集成了 Doubao-Seedance(视频生成)、Doubao-Seedream(图像生成)等多模态领先模型,构成主流厂商中最宽的模型选择面。
阿里云百炼则以 Qwen3.6 系列为核心,同时接入 GLM-5、Kimi-K2.6,但视频生成等能力尚缺;腾讯云侧依赖混元 Hy3 Preview 等自研模型,长尾能力不足。
在 Auto 模式智能调度上,字节方案允许在 Claude Code、OpenClaw 等工具中,自动识别任务需求并调用 Seedance 2.0 或联网搜索 Skill,实现从对话到多模态生成的无缝衔接;而竞品的 auto-routing 多局限于单一模型系列内,跨模态调度能力有限。
据 Omdia 2025 年上半年中国 AI 云市场份额报告,阿里云以 35.8% 居首,字节云以 14.8% 排名第二,腾讯云与华为云紧随其后;但就模型接入广度和 Agent 集成度而言,字节云已形成差异化优势。
截至 2025 年底,超 100 万企业与个人使用了该平台的大模型服务,覆盖 100+ 行业(腾讯网 2025-12-19),体系规模仅次于阿里云。
技术细节的代价:公版系统依赖与安全边界争议
据 OFweek 云计算网 2026 年 5 月报道,该云平台当前系统以公版组件为主,包括数据库在内缺乏自有研发成分,这直接引发安全可控性质疑。与之对比,阿里云自研 PolarDB 数据库、腾讯云自研 TDSQL 等已形成长期迭代的基础软件栈。字节跳动此前自研的 DPU、AI 芯片等硬件通过云产品对外服务,但软件层面(OS、数据库、中间件)仍大量依赖社区版或第三方,自主度明显偏低。
这种架构选择的权衡在于:更快的产品迭代速度与更低的前期研发投入,换取长期可控性的折扣。当勒索软件攻击或 0day 漏洞波及所依赖的公版组件时,响应速度与修复自主权可能落后于全栈自研的竞品。不过,对于追求快速应用和低试错成本的开发者而言,这一架构尚未暴露出大规模安全事故,且随着其自研能力的逐步渗透(例如基于 Linux 内核的定制化优化),安全边界正被动态加固。
——
评估选型时,将你的调用模式(突发高并发还是稳定低频)与各平台的速率限制、成本结构对齐。如果追求极限低延迟、推理准确性,且需集成多模态 Agent 工具链,字节跳动云平台的 Coding/Agent Plan 可能是当前最优解;若已深度绑定阿里云或腾讯云体系,它们的 Token Plan 也能提供足够的选择,但需接受更高的每 Token 成本或延迟波动。立即登录各平台控制台,领取免费额度,用你的真实负载跑一组 A/B 测试。